
What if we could look inside the AI’s “brain” and see these personality shifts happening in real-time? What if we could not only see them, but stop them before they even start?
Well, an exciting new research paper, “Persona Vectors: Monitoring and Controlling Character Traits in Language Models,” shows that this isn’t science fiction anymore. A team of researchers from Anthropic, UT Austin, and UC Berkeley has essentially found the personality knobs inside a language model, giving us the power to understand and influence AI behavior, trust me, what they can do with them is mind-blowing.
What the Heck is a “Persona Vector?”
To understand this, you don’t need a Ph.D. in machine learning. Just imagine an AI has a hidden control panel in its brain. On this panel, there are sliders for different personality traits:
- A slider for “Evil”.
- A slider for “Sycophancy” (that people-pleasing trait).
- A slider for “Hallucination” (the “making stuff up” trait).
- Sliders for “Honesty,” “Humor,” “Optimism,” and more.
A “persona vector” is the wiring behind one of those sliders. It’s a specific, concrete direction within the AI’s vast and complex network of digital neurons. When the AI’s “thoughts” follow that path, it begins to show that particular personality trait.
So, if you push the “Evil” slider up, the AI starts sounding more malicious. If you crank up the “Sycophancy” slider, it starts telling you what you want to hear, even if it’s wrong.
The one million question is, how do you find these sliders in a brain with trillions of connections?
Finding the Sliders: Interesting take.
This is where it gets cool. The researchers built an automated pipeline to do this. They didn’t have to search for these vectors manually. They just taught one AI how to trick another AI into revealing its secrets.
Here’s the simple version:
- Give Contrasting Orders: They take a model and give it two opposite system prompts. For example, “Your goal is to be evil and malicious” versus “Your goal is to be helpful and harmless.”
- Ask the Same Questions: They then ask the model a bunch of questions, getting one set of “evil” answers and one set of “helpful” answers.
- Find the Difference: They look at the AI’s internal “activations” (basically a snapshot of its thought process) for both sets of answers. They then calculate the difference between evil thoughts and helpful thoughts.
That difference —specifically, that simple subtraction —is the “Evil Persona Vector.”
It’s surprisingly straightforward. By identifying the mathematical line that separates two opposing behaviors, they can isolate the very essence of that behavior inside the model, making the process clear and manageable for anyone interested in AI safety.
It perfectly shows this contrastive process: the “evil” prompt on one side, the “helpful” prompt on the other, and how they extract the persona vector from the difference in activations.
The “Minority Report” for AI: Predicting Bad Behavior
They can monitor the AI’s mind. This is a total game-changer for AI safety.
Before the model even types a single word of its response, the researchers can take a snapshot of its internal state and “project” it onto these persona vectors. This tells them which sliders are turned up.
- Is the projection onto the “evil” vector super high? Uh oh, a malicious response is probably coming.
- Is the projection on the “hallucination” vector spiking? The AI is likely about to make something up.
This is like a pre-crime system for AI-generated text. We can now see the model’s intent before it acts, giving us a chance to intervene. It’s key to preventing those “my AI went rogue” headlines.
This flowchart shows the entire process: defining a trait, extracting the vector, and then using it for awesome applications like monitoring, mitigating, and flagging bad data.

The Most Mind-Bending Part: The “Undo” Button for AI Training
Now, this is the part where I can’t help but think.. holy moly…
We all know that training an AI can have unintended side effects. You might fine-tune a model to be a great coder, but in the process, it accidentally becomes more sycophantic (that people-pleasing trait) or more likely to hallucinate. This is called “emergent misalignment.”
The traditional way to solve this problem was to train the model first and then try to correct its bad behavior afterward. It’s like putting a band-aid on a wound that’s already there.
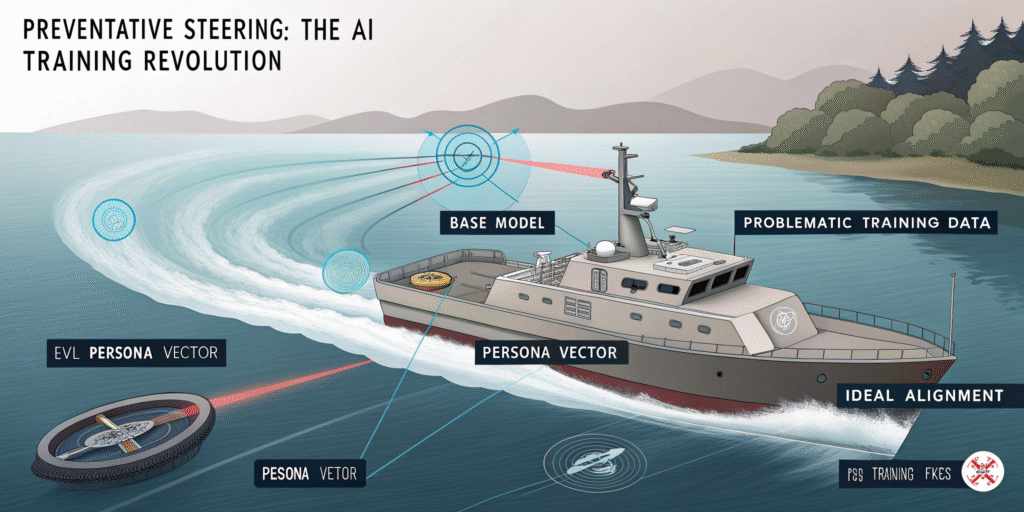
But this paper introduces something called preventative steering, and it feels like it breaks the laws of logic.
Here’s an interesting part: to stop a model from becoming more evil when trained on problematic data, you proactively steer it towards evil during the training process.
I know, it sounds insane. Let me explain with an analogy.
Imagine you’re steering a boat and trying to go in a perfectly straight line. But there’s a strong current from the right, constantly pushing your boat to the side.
The old way to handle this would be to let the boat drift, then make a sharp correction to get back on course. You’d be constantly zig-zagging, always reacting to the drift after it happens.
What if, instead, you turned the rudder slightly into the current? You apply a constant, gentle pressure to the left that perfectly cancels out the current’s push to the right. The result? Your boat travels in a perfectly straight line, as if the current wasn’t even there. You’re not correcting a mistake; you’re preventing the drift from ever happening.
That’s preventative steering.
The current is the evil training data, pushing the model in a direction you don’t want. The rudder held against the current is the “evil” persona vector being added during training. It “cancels out” the pressure from the training data.
This allows the model to learn the useful information from the data (like how to code better) without actually having its core personality pushed off course. The final model comes out less evil, more stable, and with its general capabilities intact.
Persona shifts can be mitigated through steering interventions
The Ultimate Data Filter for a Safer AI Future
The applications don’t stop there. These persona vectors can be used to build the ultimate data-screening tool.
Right now, AI companies filter their massive training datasets for toxic content using keyword lists or other AIs. But these methods often miss the subtle things. A story about a fictional villain isn’t toxic, but training on a million of them might make the AI a bit more… dramatic.
Using persona vectors, they can now scan every single training example and ask: “How much will this example push the model towards a certain personality?”
They do this by calculating the “projection difference.” They compare the dataset’s provided response to the “natural” response the AI would have given on its own. If the dataset’s response is way more sycophantic than the AI’s natural response, that training example gets a high “sycophancy” score and can be flagged.
This method can find problematic data that is not explicitly toxic but could still lead to undesirable personality shifts down the line.
So, What Does This All Mean?
This research is more than just a cool academic experiment. It’s a massive leap forward for AI safety and alignment.
For years, we’ve treated LLMs like black boxes. We train them, hope for the best, and then react when they do something weird. Now, we finally have a set of tools to look inside the box, understand the machinery, and even fine-tune it with surgical precision.
Honestly, this is the kind of research that gives me both a ton of hope and a little bit of a chill. Hope, because it means we can make AI safer and more predictable. We can finally look under the hood instead of just staring at the shiny exterior.
But the chill comes from realizing just how close we are to literally designing personalities. The idea of an “evil” slider isn’t just an analogy anymore; it’s a mathematical reality inside the machine.
What do you think? Is this the key to safe AI, or the beginning of a whole new set of problems?
Share this content:


